Human-Object Interaction (HOI) is vital for advancing simulation, animation, and robotics, enabling the
generation of long-term, physically plausible motions in 3D environments. However, existing methods
often fall short of achieving physics realism and supporting diverse types of interactions. To address
these challenges, this paper introduces a unified Human-Object Interaction framework that provides unified
control over interactions with static scenes and dynamic objects using language commands. The interactions
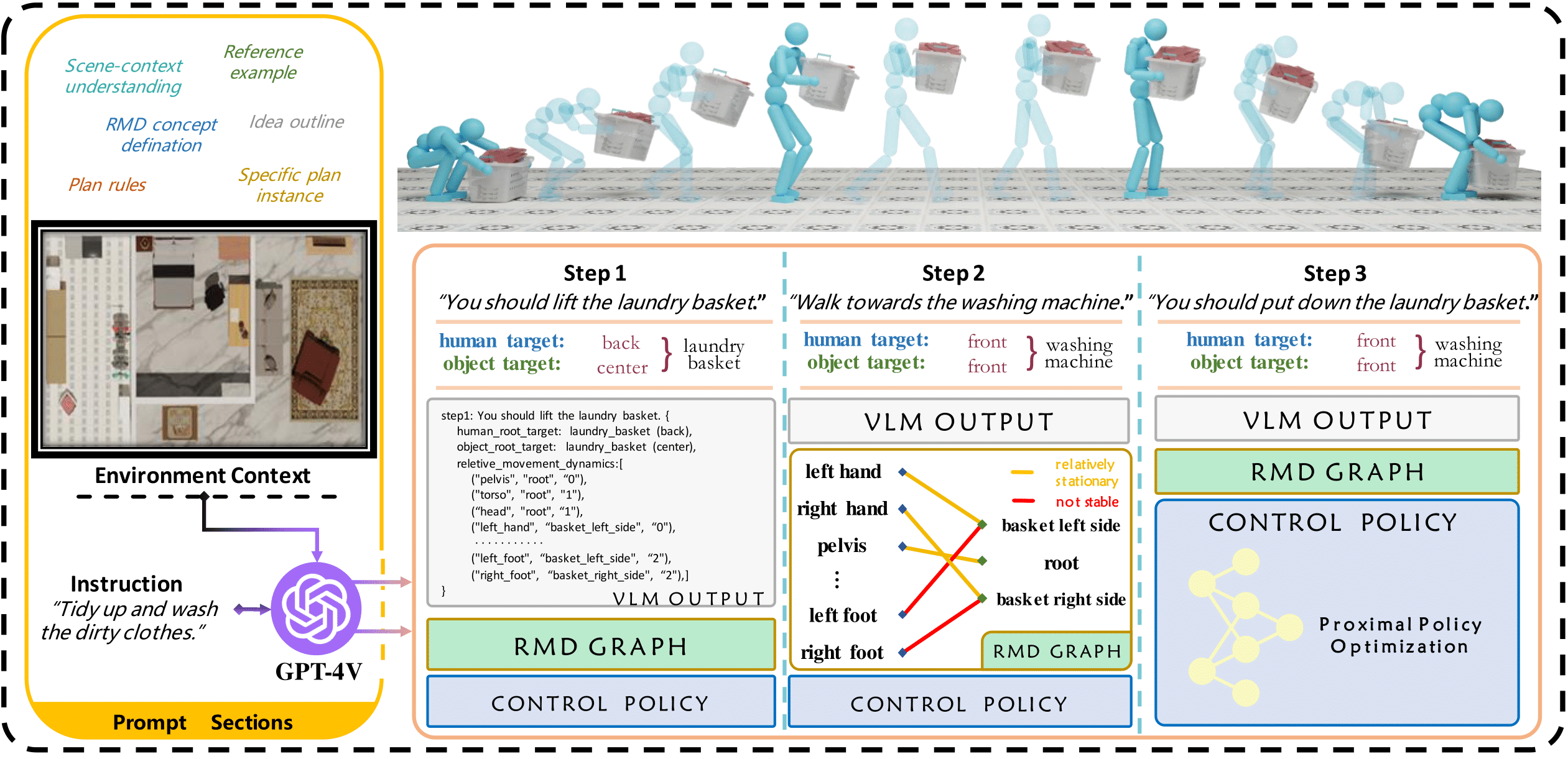
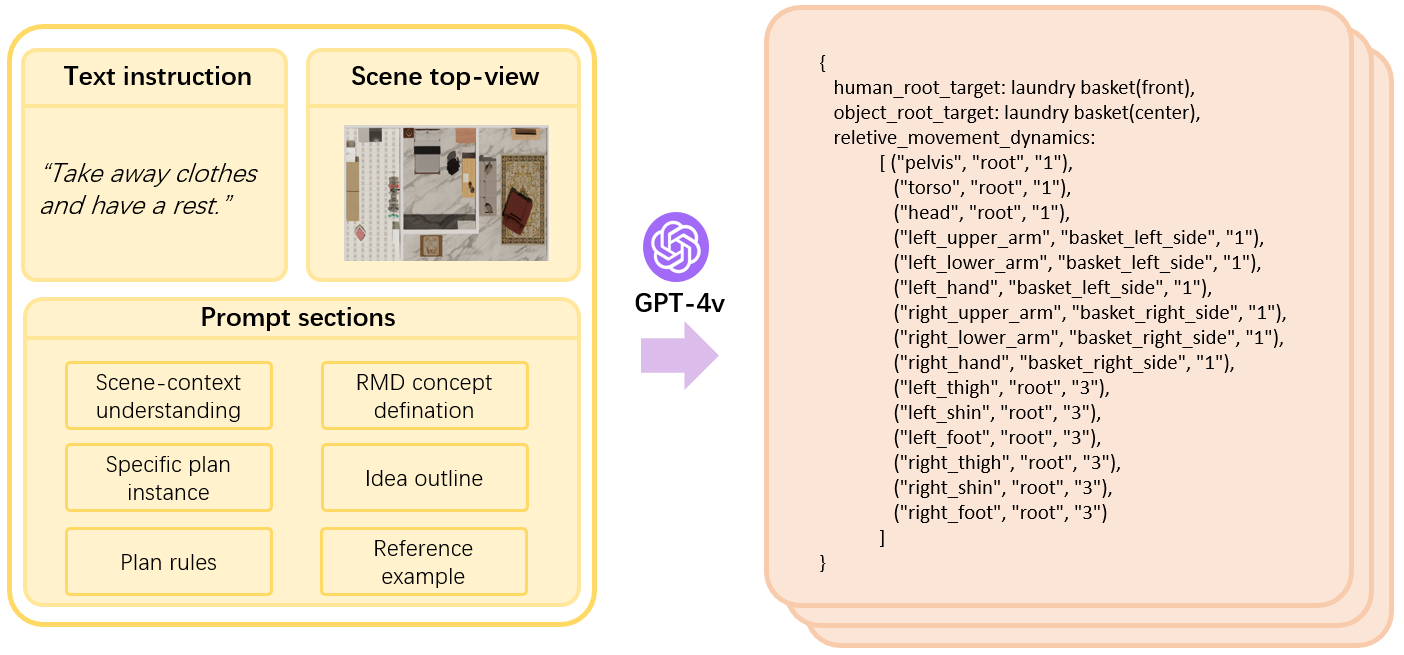
between human and object parts can always be described as the continuous stable Relative Movement Dynamics (RMD)
between human and object parts. By leveraging the world knowledge and scene perception capabilities of
Vision-Language Models (VLMs) , we translate language commands into RMD diagrams, which are used to guide
goal-conditioned reinforcement learning for sequential interaction with objects. Our framework supports
long-horizon interactions among dynamic, articulated, and static objects. To support the training and
evaluation of our framework, we present a new dataset named Interplay, which includes multi-round task plans
generated by VLMs, covering both static and dynamic HOI tasks. Extensive experiments demonstrate that our
proposed framework can effectively handle a wide range of HOI tasks, showcasing its ability to maintain
long-term, multi-round transitions.